
Preparing for the Cloud
The last post gave Manuscript Alert a new face. Three-column layout, dark mode, real search controls. It looked like a modern application. But behind the scenes, the new interface was still talking to the same backend from eight posts ago, the same way it always had.
Think of a house that's been completely renovated inside. New kitchen, open floor plan, beautiful finishes. But it's still running on a generator in the backyard and getting water from a well. It works. It's livable. But it can't connect to the neighborhood grid until someone runs proper utility lines.
That's what this post is about. Not building new features, not changing what DK sees when he searches for Alzheimer's papers. This is about running the utility lines so that everything we build next (cloud hosting, a real database, intelligent search) can just plug in.
Living Off the Grid
The backend had one address for everything. Every request, whether it was fetching papers or saving settings or checking if the server was alive, went to the same flat set of locations. No version numbers. No organization beyond "here's where the thing lives."
This worked fine when the app ran on one laptop. But cloud services need something more structured. When you deploy to the internet, you need to be able to update the backend without breaking every device that's already talking to it. You need addresses that can evolve. You need room to say "version one lives here, and when version two is ready, it lives next door, and both work until everyone has moved over."
So I created a proper addressing system. Every endpoint got a versioned path. The old addresses still work (nothing breaks), but the new ones are what the frontend now uses. And the new system already has space reserved for features that don't exist yet, like a knowledge base for saved papers.
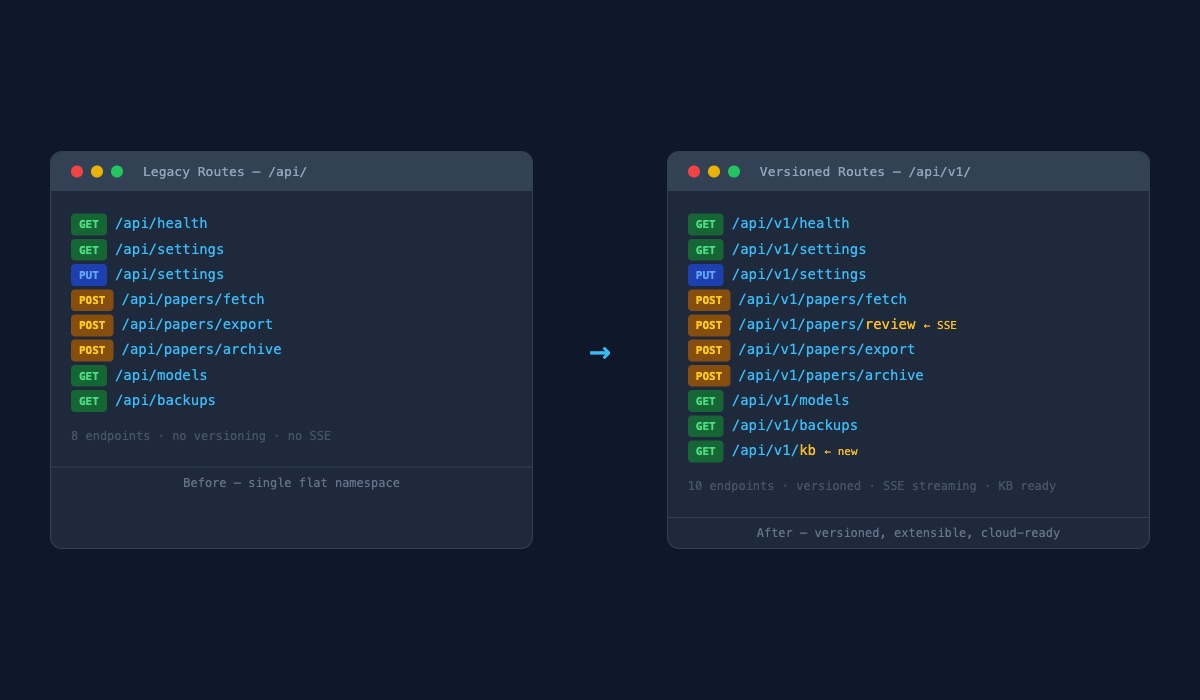
Both sets of addresses live side by side. The old ones aren't going anywhere yet. If something went wrong with the new system, DK could fall back without skipping a beat. Zero disruption, always.
Three Empty Slots
The house needed utility hookups, but the utilities themselves haven't arrived yet. So I installed three connection points and labeled them: one for a database, one for an intelligence service, one for a knowledge store.
Right now, all three are empty. The app runs perfectly without them. Papers still come from the same sources. Settings still save to the same files. Nothing changed about DK's daily workflow.
But the moment we're ready to move paper storage to a real database, we fill in one slot. When we add intelligent paper discovery, we fill in another. When we build a knowledge base of saved research, the third. Each future step in the migration plan has a hookup waiting for it. No rewiring needed.
The configuration itself moved from being hardwired into the code to being set through environment variables. Think of it like switching from a house where the thermostat is welded to 72 degrees to one where you can adjust it from a panel. Same house, same heating system, but now it's configurable from the outside. That's what cloud deployment needs: the ability to tell the app where its database lives, what keys to use, which services to connect to, all without touching the code itself.
The End of the Blank Stare
Here's the change DK actually noticed.
Before this work, searching for papers meant clicking a button and staring at a loading spinner. The backend would go off and query arXiv, bioRxiv, PubMed, score everything, filter the results, and eventually come back with an answer. Fifteen to thirty seconds of nothing. Just a spinning circle and the hope that it was still working.
Now the backend talks back while it works. "Fetching from arXiv... found 47 papers." A moment later: "Fetching from bioRxiv... 23 papers." Then PubMed, batch by batch, because PubMed has the most results and takes the longest. "Batch 1 of 3... 52 papers so far." "Batch 2 of 3... 104 papers." Each update streams to the frontend the instant it happens.
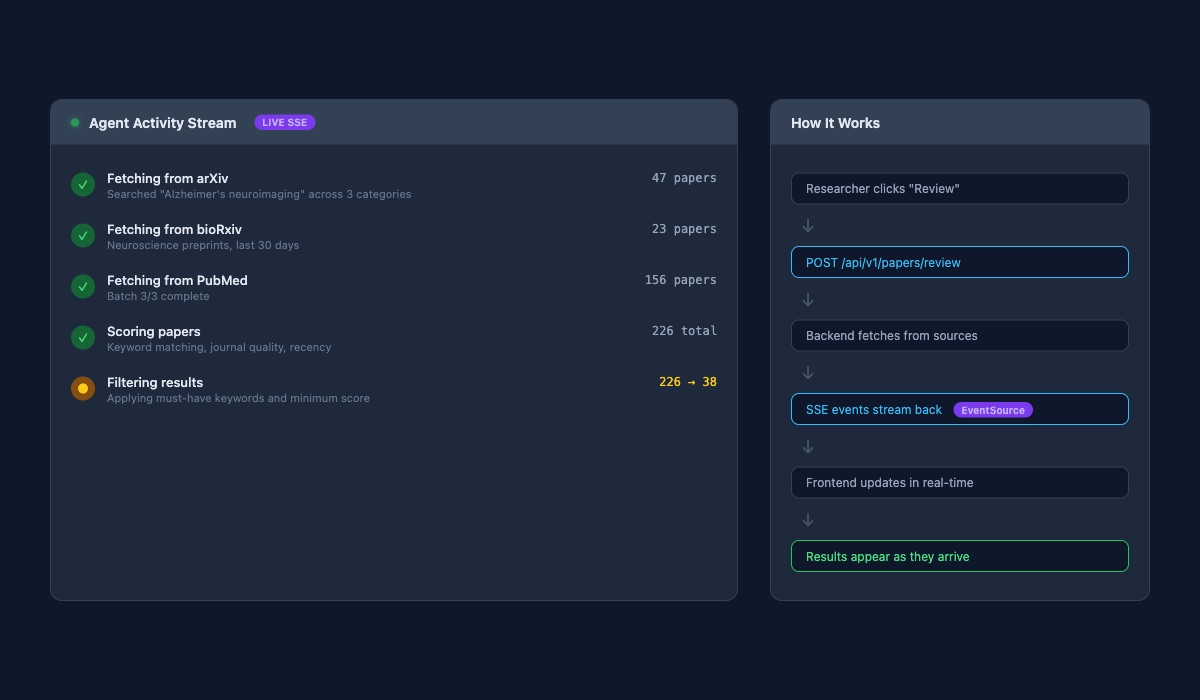
After all the papers arrive, the scoring phase starts: "Scoring 226 papers against keywords, journal quality, recency." Then filtering: "226 papers narrowed to 38." Every stage visible. Every number updating live.
The difference is like calling a restaurant and being told "your order will be ready" versus watching the kitchen through a glass wall. Same food, same wait time. But one leaves you wondering if they forgot about you, and the other lets you see your meal taking shape.
DK mentioned that the search "feels faster now," even though the actual fetch time hasn't changed. Perception matters. When you can see progress, waiting doesn't feel like waiting.
Running Both Worlds
The trickiest part was making sure the old system and the new one coexisted. The frontend from Blog 9 was already built to talk to the new versioned addresses. But the old addresses needed to keep working too, because the transition isn't instant and nothing should break if we need to roll back.
So the backend registers both. Every old route still responds exactly as it always did. Every new route offers the same data through the versioned path. The frontend uses the new ones. The tests cover both. It's the same house, now with both the generator and the grid hookup, running in parallel until we're confident enough to unplug the generator.
65 files changed across this commit. About 2,900 lines added, 1,100 removed. The biggest additions were the real-time streaming system and the new versioned routes. The net code grew, but most of it is preparation: scaffolding for features that will arrive in the next few posts.
What This Unlocks
None of this changed what DK does day to day. He still searches for papers, adjusts his keywords, and checks what's new in Alzheimer's research. The real-time stream is the one visible improvement, and he likes it.
But under the surface, the app is ready for a different kind of life. It has proper addresses that can evolve without breaking existing connections. It has hookups waiting for a database, an intelligence engine, and a knowledge store. It has a configuration system that lets the cloud tell the app how to behave, instead of the app having everything baked in.
The house is wired. The hookups are in place. Next, we start connecting utilities.
What's Next
The first utility to connect is a real database. Right now, papers and settings live in files on disk. That works for one laptop, but it can't scale, can't be shared, and can't be searched intelligently. In the next post, we'll move everything to a proper database, and the hookup we installed today will make the connection seamless.